HIVEDmind
Why we built our own geospatial data pipeline using OpenStreetMap
Most logistics teams rely on third-party mapping APIs. You integrate, pay per request, and work within the limits of someone else’s data. At HIVED, we built our own geospatial data pipeline using OpenStreetMap so we can control how location data is processed, queried, and updated to better support how delivery actually works.

Henry Searle
·
3 min read

Most teams rely on third-party mapping APIs, paying per request and working within fixed data limits. That approach works, but it comes with constraints around cost, flexibility, and control. At HIVED, location data underpins every delivery, so instead of relying on external providers, we built our own geospatial data pipeline using OpenStreetMap. This allows us to control how geographic data is processed, updated, and used across our network.
Processing raw OpenStreetMap data for delivery use
We ingest England’s road network from OpenStreetMap on a weekly basis as part of our geospatial data pipeline. The pipeline runs as an ECS job and performs a two-pass parse: first extracting drivable road geometries, then building junction topology to understand how roads connect within our geospatial dataset. We then apply delivery-specific filtering, reclassifying road types such as driveways, parking aisles, and pedestrianised streets to reflect how they are actually used in last-mile delivery. The output is written to FlatGeobuf, a spatially optimised binary format, and stored in S3. Because we own this geospatial processing pipeline, we can update how OpenStreetMap data is handled at any time.
Using FlatGeobuf for fast geospatial queries
The full OpenStreetMap dataset for England is around 1.5GB, but most geospatial queries only require a small subset of that data. FlatGeobuf is designed for efficient geospatial querying by storing features are sorted using a Hilbert curve so that roads which are geographically close are also close together in the file, and a packed R-tree spatial index allows us to quickly locate relevant features without scanning the entire dataset.
When querying, we use the index to request only the required parts of the file. Because FlatGeobuf supports HTTP range requests, we make partial reads from S3 without loading the full dataset. This means our geospatial queries are precise, efficient, and avoid unnecessary data reads. In practice, we typically read around 1MB instead of the full dataset.
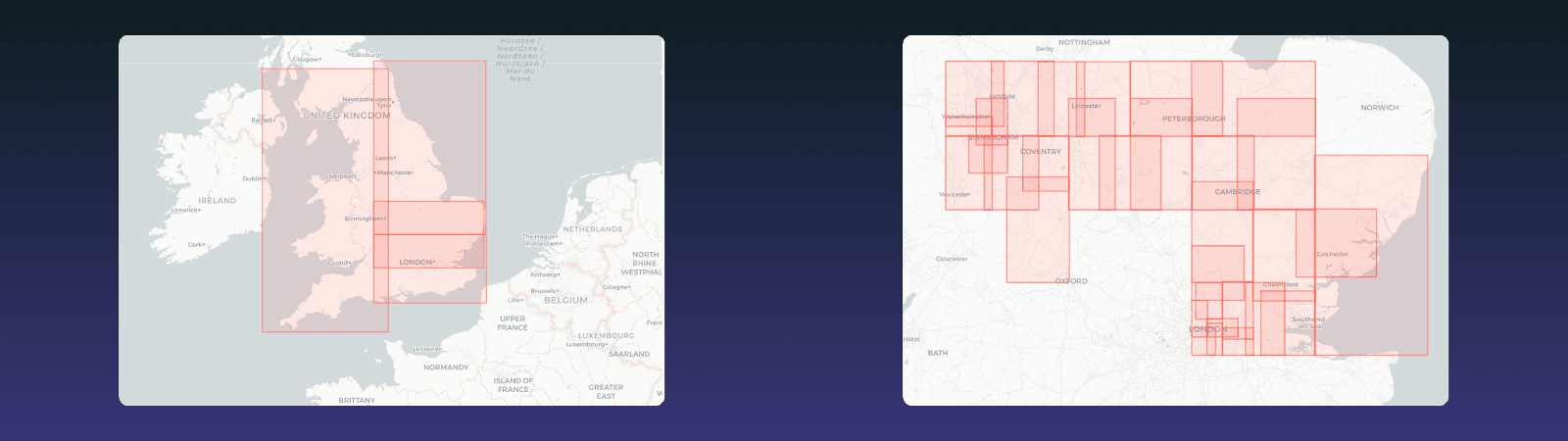

Querying geospatial data directly from S3
Instead of using a spatial database such as PostGIS, we query geospatial data directly from S3. Our Lambda functions read the FlatGeobuf file using HTTP range requests, allowing partial reads of the geospatial dataset. A custom ReadSeeker implementation manages these reads, supported by a small in-memory cache. The spatial index is traversed in memory, and only the required feature data is fetched. This approach removes the need for a spatial database, reducing infrastructure complexity while still supporting fast geospatial queries. Each function operates independently, and the system scales without additional configuration.
Zero-downtime geospatial data updates
We refresh our geospatial dataset weekly to incorporate updates from OpenStreetMap, including new roads, changes, and corrections. Each pipeline run generates a new timestamped FlatGeobuf file in S3. Once the file is fully written, a metadata file is updated to reference the new version of the geospatial data. Consumers resolve the current file during initialisation, ensuring they always read from a complete dataset. Versioned prefixes prevent any process from accessing partially written data. This ensures that geospatial data updates can be applied safely without downtime or disruption.
Encoding delivery logic into geospatial data
Our pipeline does more than process map data. It encodes delivery logic directly into the geospatial dataset. Road types are defined based on real-world delivery operations, ensuring routing reflects how deliveries actually occur.
Large road segments are split to maintain a balanced spatial index and improve geospatial query precision. Junction topology is preserved for routing, while unnecessary payload is reduced. These decisions ensure the geospatial data is shaped by operational needs rather than generic mapping assumptions.
Why this matters
Building our own geospatial data pipeline using OpenStreetMap gives us control over a critical part of the delivery system. We are not dependent on third-party mapping APIs, pricing models, or update cycles. We can process, query, and update geographic data efficiently, while keeping operational overhead low. The result is a geospatial system designed around how delivery actually works, with performance and flexibility built in from the start.
To dive deeper into the technology behind HIVED, read our engineering blog on Go and our data blog on building a scalable analytics stack. Follow us on LinkedIn for more HIVEDmind updates.



" height="18px" id="WXhVeA1oH" transform="translate(4.16 3)" width="15.680039999999998px"/></svg>)
" height="18px" id="B9Ck5Ljyr" transform="translate(3 3)" width="18px"/></svg>)
" height="18px" id="v2_jQqFYe" transform="translate(3 3)" width="18px"/></svg>)